主管:中国科学院
主办:中国优选法统筹法与经济数学研究会
中国科学院科技战略咨询研究院
主办:中国优选法统筹法与经济数学研究会
中国科学院科技战略咨询研究院
中国管理科学 ›› 2025, Vol. 33 ›› Issue (11): 29-40.doi: 10.16381/j.cnki.issn1003-207x.2024.0438cstr: 32146.14.j.cnki.issn1003-207x.2024.0438
李刚1, 仇朝朝1, 张志鹏2( ), 秦思萌1, 薛星楠1
), 秦思萌1, 薛星楠1
收稿日期:2024-03-28
修回日期:2024-07-05
出版日期:2025-11-25
发布日期:2025-11-28
通讯作者:
张志鹏
E-mail:zhangzhipeng@sjtu.edu.cn
基金资助:
Gang Li1, Chaochao Qiu1, Zhipeng Zhang2(), Simeng Qin1, Xingnan Xue1
Received:2024-03-28
Revised:2024-07-05
Online:2025-11-25
Published:2025-11-28
Contact:
Zhipeng Zhang
E-mail:zhangzhipeng@sjtu.edu.cn
摘要:
本文基于上市公司年报、省级政府工作报告和央行货币政策报告等多源文本数据,通过提取文本相似度、文本语调、文本可读性等在内的多维度文本指标,结合上市公司财务数据等非文本指标,采用特征增强树模型(Augboost)对上市公司欺诈进行预测。基于2001—2020年我国A股制造业上市公司的实证结果表明:(1)多源文本指标提供了额外的信息增量。(2)不同类型的文本所带来的信息增量不同:相较于上市公司年报和省级政府工作报告文本,央行货币政策文本提供的信息增量最为显著。(3)相较于逻辑回归等常见算法,本文所采用的特征增强树能够更准确地预测上市公司是否存在欺诈行为。
中图分类号:
李刚,仇朝朝,张志鹏, 等. 基于多源文本数据和特征增强树模型的上市公司欺诈预测研究[J]. 中国管理科学, 2025, 33(11): 29-40.
Gang Li,Chaochao Qiu,Zhipeng Zhang, et al. Research on Predicting Corporate Fraud of Listed Companies Based on Multi-Source Text Data and Feature-Augmented Tree Models[J]. Chinese Journal of Management Science, 2025, 33(11): 29-40.

图1
Augboost训练过程"
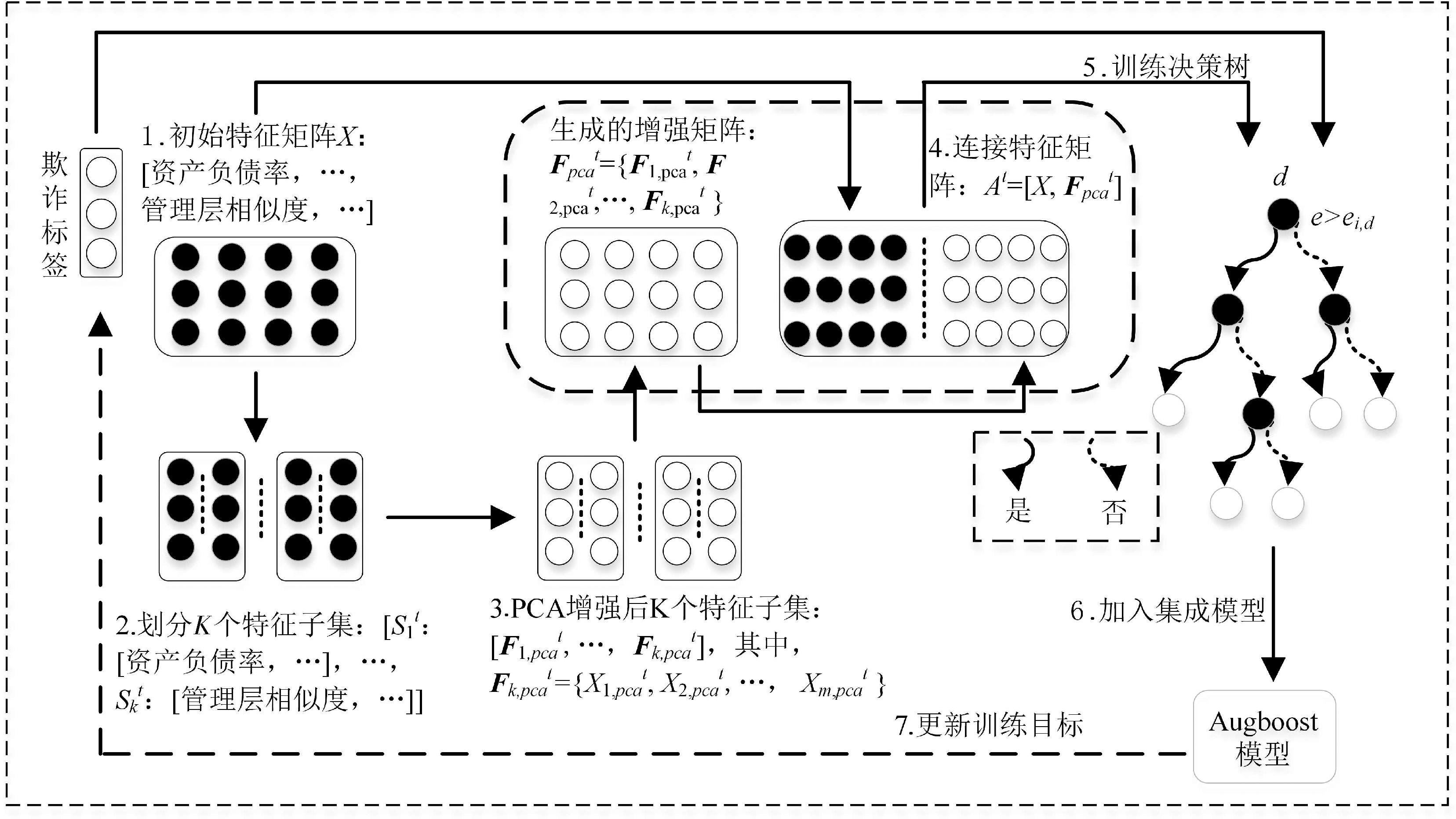
表1
综合情感词典"
| 序号 | 1 | 2 | 3 | … | 4217 | … | 6748 |
|---|---|---|---|---|---|---|---|
| 积极词 | 敬献 | 敬业 | 爱国心 | … | 尊法 | ||
| 消极词 | 贫乏 | 劫数 | 短视 | … | 猖狂 | … | 哀悼 |
表2
上市公司年报文本指标"
| 股票代码-年份 | 上市公司年报文本 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 文本相似度 | 文本净语调 | 文本负语调 | 文本可读性 | 短视指标 | 竞争战略 | |||||
| 短视综合指标 | 数月 | … | 还款压力 | Cost | Diff | |||||
| 000004-2010 | 0.690 | 0.754 | 0.123 | 56.857 | 0.259 | 0.833 | 0.965 | 0.003 | 0.001 | |
| 000004-2011 | 0.590 | 0.448 | 0.276 | 52.313 | 0.295 | 0.474 | 0.549 | 0.005 | 0.001 | |
| … | … | … | … | … | … | … | … | … | … | … |
| 000016-2001 | 0.597 | 0.398 | 0.301 | 43.645 | 0.193 | 1.242 | 1.440 | 0.008 | 0.003 | |
| 000016-2002 | 0.523 | 0.813 | 0.093 | 191.286 | 0.000 | 1.085 | 1.257 | 0.003 | 0.005 | |
| … | … | … | … | … | … | … | … | … | … | … |
| 688981-2020 | 0.825 | 0.171 | 0.414 | 55.247 | 0.032 | 0.102 | 0.096 | 0.003 | 0.002 | |
表3
央行和政府文本指标"
| 股票代码-年份 | 央行文本 | 省级政府工作报告文本 | ||||||
|---|---|---|---|---|---|---|---|---|
| 文本相似度 | 文本净语调 | 文本负语调 | 文本可读性 | 文本相似度 | 文本净语调 | 文本负语调 | 文本可读性 | |
| 000004-2010 | 0.313 | 0.582 | 0.209 | 45.461 | 0.699 | 0.862 | 0.069 | 33.813 |
| 000004-2011 | 0.421 | 0.427 | 0.287 | 45.096 | 0.707 | 0.903 | 0.048 | 28.723 |
| … | … | … | … | … | … | … | … | … |
| 000016-2001 | 0.512 | 0.499 | 0.251 | 46.161 | 0.655 | 0.848 | 0.076 | 34.569 |
| 000016-2002 | 0.512 | 0.552 | 0.224 | 48.429 | 0.736 | 0.811 | 0.094 | 31.425 |
| … | … | … | … | … | … | … | … | … |
| 688981-2020 | 0.484 | 0.584 | 0.208 | 45.718 | 0.702 | 0.171 | 0.414 | 55.247 |
表4
增强前后特征矩阵"
| 样本数 | 初始特征矩阵 | |||
|---|---|---|---|---|
| X1 | X2 | … | X146 | |
| 1 | 1.6175 | 1.2867 | … | 0.005233 |
| 2 | 0.3553 | 0.3441 | … | 0.001661 |
| 3 | 1.75361 | 1.1987 | … | 0.004289 |
| … | … | … | … | … |
| 12866 | 0.3010 | 0.1617 | … | 0.005182 |
| 12867 | 1.3127 | 0.9226 | … | 0.000947 |
| 增强后矩阵 | ||||
| X’1 | X’2 | … | X’146 | |
| 1 | -0.2557714 | -0.03033657 | … | -0.426517 |
| 2 | -0.2569253 | -0.06300148 | … | 0.0241909 |
| 3 | 0.18951760 | -0.06886076 | … | 0.0418108 |
| … | … | … | … | … |
| 12866 | -0.2366145 | -0.04575666 | … | -0.033644 |
| 12867 | -0.2381984 | 0.002320920 | … | 0.7880405 |
表5
欺诈模型精度对比结果"
| 序号 | 模型 | AUC | KS | G-mean | F-score | Precision | Recall | Accuracy | BM |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Augboost | 0.723 | 0.340 | 0.652 | 0.394 | 0.298 | 0.581 | 0.707 | 0.313 |
| 2 | LR | 0.466 | 0.014 | 0.081 | 0.013 | 0.240 | 0.007 | 0.834 | 0.013 |
| 3 | NB | 0.536 | 0.025 | 0.164 | 0.283 | 0.165 | 0.983 | 0.184 | 0.081 |
| 4 | DT | 0.560 | 0.118 | 0.480 | 0.266 | 0.260 | 0.272 | 0.754 | 0.120 |
| 5 | KNN | 0.518 | 0.026 | 0.197 | 0.067 | 0.218 | 0.040 | 0.819 | 0.029 |
| 6 | RF | 0.720 | 0.058 | 0.100 | 0.020 | 0.563 | 0.010 | 0.836 | 0.331 |
| 7 | LDA | 0.685 | 0.070 | 0.172 | 0.056 | 0.397 | 0.030 | 0.834 | 0.283 |
| 8 | ANN | 0.501 | 0.007 | 0.066 | 0.009 | 0.211 | 0.004 | 0.834 | 0.004 |
| 9 | Ada | 0.691 | 0.199 | 0.630 | 0.360 | 0.257 | 0.600 | 0.651 | 0.276 |
表6
不同指标的欺诈预测模型对比"
| 序号 | 指标组合 | AUC | KS | G-mean | F-score | Accuracy | BM | Precision | Recall |
|---|---|---|---|---|---|---|---|---|---|
| 0 | T | 0.627 | 0.188 | 0.582 | 0.314 | 0.622 | 0.169 | 0.224 | 0.529 |
| 1 | A | 0.635 | 0.208 | 0.595 | 0.328 | 0.642 | 0.197 | 0.237 | 0.534 |
| 2 | A+T | 0.674 | 0.253 | 0.615 | 0.348 | 0.658 | 0.235 | 0.253 | 0.558 |
| 3 | A+B | 0.670 | 0.258 | 0.615 | 0.350 | 0.663 | 0.238 | 0.256 | 0.553 |
| 4 | A+B+T | 0.690 | 0.273 | 0.621 | 0.357 | 0.673 | 0.250 | 0.263 | 0.554 |
| 5 | A+B+C | 0.702 | 0.304 | 0.632 | 0.372 | 0.693 | 0.276 | 0.280 | 0.555 |
| 6 | A+B+C+T | 0.720 | 0.321 | 0.647 | 0.387 | 0.700 | 0.302 | 0.291 | 0.577 |
| 7 | A+B+C+D | 0.722 | 0.327 | 0.642 | 0.384 | 0.702 | 0.294 | 0.290 | 0.565 |
| 8 | A+B+C+D+T | 0.723 | 0.340 | 0.652 | 0.394 | 0.707 | 0.313 | 0.298 | 0.580 |
表7
三类文本指标的欺诈预测"
| 模型序号 | 指标 | AUC | KS | G-mean | F-score | Accuracy | BM | Precision | Recall |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 管理层文本指标 | 0.586 | 0.140 | 0.564 | 0.297 | 0.604 | 0.133 | 0.210 | 0.511 |
| 2 | 政府文本指标 | 0.584 | 0.118 | 0.552 | 0.287 | 0.564 | 0.106 | 0.196 | 0.537 |
| 3 | 央行文本指标 | 0.605 | 0.162 | 0.578 | 0.310 | 0.580 | 0.156 | 0.212 | 0.574 |
| 4 | T | 0.627 | 0.188 | 0.582 | 0.314 | 0.622 | 0.169 | 0.224 | 0.529 |
| 5 | A | 0.635 | 0.208 | 0.595 | 0.328 | 0.642 | 0.197 | 0.237 | 0.534 |
| 6 | A+管理层文本指标 | 0.650 | 0.225 | 0.600 | 0.336 | 0.661 | 0.212 | 0.248 | 0.524 |
| 7 | A+政府文本指标 | 0.650 | 0.227 | 0.603 | 0.336 | 0.648 | 0.212 | 0.243 | 0.543 |
| 8 | A+央行文本指标 | 0.668 | 0.242 | 0.614 | 0.347 | 0.651 | 0.233 | 0.250 | 0.565 |
| 9 | A+T | 0.674 | 0.253 | 0.615 | 0.348 | 0.658 | 0.235 | 0.253 | 0.558 |
表8
模型特征重要性占比"
| 模型序号 | 指标构成 | 非文本指标% | 文本指标% | 央行文本指标% | 政府文本指标% | 管理层文本指标% |
|---|---|---|---|---|---|---|
| 2 | A+T | 57.8 | 42.2 | 7.0 | 6.9 | 28.3 |
| 4 | A+B+T | 70.5 | 29.5 | 6.0 | 5.7 | 17.8 |
| 6 | A+B+C+T | 76.2 | 23.8 | 4.1 | 4.0 | 15.7 |
| 8 | A+B+C+D+T | 84.7 | 15.3 | 0.8 | 2.8 | 11.7 |
表9
不同数据集上指标对比"
| 指标 | 数据集 | 方法 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ADT | Bag | BagNN | Boost | LMT | RF | RotFor | SGB | Augboost | ||
| KS | AC | 0.742 | 0.736 | 0.739 | 0.734 | 0.744 | 0.751 | 0.750 | 0.740 | 0.815 |
| GC | 0.429 | 0.437 | 0.487 | 0.443 | 0.403 | 0.457 | 0.431 | 0.412 | 0.467 | |
| GMC | 0.567 | 0.545 | 0.530 | 0.563 | 0.524 | 0.573 | 0.518 | 0.567 | 0.574 | |
| 综合排序 | 5 | 6.333 | 5 | 6 | 7 | 2.333 | 6 | 5.667 | 1.333 | |
| ACC | AC | 0.863 | 0.856 | 0.858 | 0.856 | 0.861 | 0.865 | 0.865 | 0.858 | 0.874 |
| GC | 0.734 | 0.744 | 0.757 | 0.740 | 0.729 | 0.751 | 0.739 | 0.728 | 0.750 | |
| GMC | 0.924 | 0.922 | 0.923 | 0.924 | 0.923 | 0.925 | 0.922 | 0.924 | 0.937 | |
| 综合排序 | 4.667 | 6.667 | 4.333 | 5.333 | 6.333 | 2 | 5.333 | 6 | 1.667 | |
| AUC | AC | 0.929 | 0.922 | 0.927 | 0.930 | 0.930 | 0.931 | 0.929 | 0.928 | 0.952 |
| GC | 0.758 | 0.779 | 0.802 | 0.772 | 0.747 | 0.789 | 0.773 | 0.751 | 0.777 | |
| GMC | 0.860 | 0.847 | 0.838 | 0.860 | 0.833 | 0.864 | 0.820 | 0.860 | 0.864 | |
| 综合排序 | 5 | 6 | 5.333 | 4 | 6.667 | 1.667 | 6.333 | 6 | 2 | |
| [1] | Dyck A, Morse A, Zingales L. Who blows the whistle on corporate fraud?[J]. The Journal of Finance, 2010, 65(6): 2213-2253. |
| [2] | 谢碧鹭. 去年超30家上市公司因财务造假被处罚[N]. 经济参考报, 2024-01-08(4). |
| Xie B L. Last year, more than 30 listed companies were punished for financial fraud[N]. Economic Information Daily, 2024-01-08(4). | |
| [3] | 中国证券监督管理委员会. 证监会要闻: 证监会依法从严打击欺诈发行、财务造假等信息披露违法行为[EB/OL]. (2024-02-04) [2024-03-08]. . |
| China Securities Regulatory Commission. CSRC News: CSRC severely crack down on fraudulent issuance, financial fraud and other information disclosure violations [EB/OL]. (2024-02-04) [2024-03-08]. . | |
| [4] | 姜富伟, 胡逸驰, 黄楠. 央行货币政策报告文本信息、宏观经济与股票市场[J]. 金融研究, 2021(6): 95-113. |
| Jiang F W, Hu Y C, Huang N. Textual information of central bank monetary policy report, macroeconomy and stock market performance[J]. Journal of Financial Research, 2021(6): 95-113. | |
| [5] | 陈艺云. 基于信息披露文本的上市公司财务困境预测: 以中文年报管理层讨论与分析为样本的研究[J]. 中国管理科学, 2019, 27(7): 23-34. |
| Chen Y Y. Forecasting financial distress of listed companies with textual content of the information disclosure: A study based MD & a in Chinese annual reports[J]. Chinese Journal of Management Science, 2019, 27(7): 23-34. | |
| [6] | 李爱华, 王迪文, 续维佳, 等. 基于多数据源融合的创业板上市公司财务造假异常检测[J]. 数据分析与知识发现, 2023, 7(5): 33-47. |
| Li A H, Wang D W, Xu W J, et al. Financial fraud detection for growth enterprise market listed companies based on data fusion[J]. Data Analysis and Knowledge Discovery, 2023, 7(5): 33-47. | |
| [7] | Bhattacharya I, Mickovic A. Accounting fraud detection using contextual language learning[J]. International Journal of Accounting Information Systems, 2024, 53: 100682. |
| [8] | Purda L, Skillicorn D. Accounting variables, deception, and a bag of words: Assessing the tools of fraud detection[J]. Contemporary Accounting Research, 2015, 32(3): 1193-1223. |
| [9] | 陈述, 游家兴, 朱书谊. 地方政府工作目标完成度与公司盈余管理——基于政府工作报告文本分析的视角[J]. 会计研究, 2022(6): 32-42. |
| Chen S, Yong J X, Zhu S Y. The completion degree of government work objectives and earnings management: From the perspective of government work report[J]. Accounting Research, 2022(6): 32-42. | |
| [10] | 林建浩, 陈良源, 罗子豪, 等. 央行沟通有助于改善宏观经济预测吗?——基于文本数据的高维稀疏建模[J]. 经济研究, 2021, 56(3): 48-64. |
| Lin J H, Chen L Y, Luo Z H, et al. Does central bank communication improve macroeconomic forecasting? High-dimensional sparse modeling based on text data[J]. Economic Research Journal,2021,56(3): 48-64. | |
| [11] | 胡楠, 邱芳娟, 梁鹏. 竞争战略与盈余质量——基于文本分析的实证研究[J]. 当代财经, 2020(9): 138-148. |
| Hu N, Qiu F J, Liang P. Competitive strategy and earnings quality: An empirical study based on text analysis[J]. Contemporary Finance & Economics, 2020(9): 138-148. | |
| [12] | 胡楠, 薛付婧, 王昊楠. 管理者短视主义影响企业长期投资吗?——基于文本分析和机器学习[J]. 管理世界, 2021, 37(5): 139-156+11+19-21. |
| Hu N, Xue F J, Wang H N. Does managerial myopia affect long-term Investment? Based on text analysis and machine learning[J]. Journal of Management World, 2021, 37(5): 139-156+11+19-21. | |
| [13] | 钱爱民, 朱大鹏. 财务报告文本相似度与违规处罚——基于文本分析的经验证据[J].会计研究,2020(9): 44-58. |
| Qian A M, Zhu D P. Financial report textual similarity and the likelihood of regulatory penalties: Based on the empirical evidence of textual analysis[J]. Accounting Research, 2020(9): 44-58. | |
| [14] | 李双燕, 蒋丽华, 卞舒晨. 年报文本情绪与上市公司违规行为识别——基于机器学习文本分析方法的实证研究[J]. 当代经济科学, 2023, 45(6): 97-109. |
| Li S Y, Jiang L H, Bian S C. Annual reports’ tone and violation behavior identification of listed companies: Evidence from textual analysis based on machine learning[J].Modern Economic Science,2023,45(6): 97-109. | |
| [15] | 郭松林, 宁祺器, 窦斌. 上市公司年报文本增量信息与违规风险预测——基于语调和可读性的视角[J]. 统计研究, 2022, 39(12): 69-84. |
| Guo S L, Ning Q Q, Dou B. Listed companies' annual report incremental text information and fraud risk prediction: From the perspective of tone and readability[J]. Statistical Research, 2022, 39(12): 69-84. | |
| [16] | 刘逸爽, 陈艺云. 管理层语调与上市公司信用风险预警——基于公司年报文本内容分析的研究[J]. 金融经济学研究, 2018, 33(4): 46-54. |
| Liu Y S, Chen Y Y. Tone at the top and credit risk warning for listed companies: Textual analysis of company annual reports[J]. Financial Economics Research, 2018, 33(4): 46-54. | |
| [17] | 伍翕婷, 游家兴, 于明洋. 政府言行一致与企业股价崩盘风险[J]. 系统工程理论与实践, 2024, 44(3): 853-873. |
| Wu X T, You J X, Yu M Y. Government’s actions according with words and stock price crash risk[J]. Systems Engineering-Theory & Practice, 2024, 44(3): 853-873. | |
| [18] | 陈艺云. 基于文本信息的上市中小企业财务困境预测研究[J]. 运筹与管理, 2022, 31(4): 136-143. |
| Chen Y Y. Financial distress prediction for listed SME based on the text information[J]. Operations Research and Management Science, 2022, 31(4): 136-143. | |
| [19] | 唐晓波, 谭明亮, 李诗轩, 等. 企业破产预测系统模型构建及实现研究[J].情报学报,2019,38(10):1051-1065. |
| Tang X B, Tan M L, Li S X, et al. Research on construction and implementation of a corporate bankruptcy prediction system model[J]. Journal of the China Society for Scientific and Technical Information, 2019, 38(10): 1051-1065. | |
| [20] | Altman E I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy[J]. The Journal of Finance, 1968, 23(4): 589-609. |
| [21] | 方匡南, 范新妍, 马双鸽.基于网络结构Logistic模型的企业信用风险预警[J].统计研究,2016,33(4): 50-55. |
| Fang K N, Fan X Y, Ma S G. Forecasting of enterprise’s credit risk based on network-logistic model[J]. Statistical Research, 2016, 33(4): 50-55. | |
| [22] | Yu L, Yao X, Wang S, et al. Credit risk evaluation using a weighted least squares SVM classifier with design of experiment for parameter selection[J]. Expert Systems with Applications, 2011, 38(12): 15392-15399. |
| [23] | Lee T S, Chiu C C, Chou Y C, et al. Mining the customer credit using classification and regression tree and multivariate adaptive regression splines[J]. Computational Statistics & Data Analysis, 2006, 50(4): 1113-1130. |
| [24] | 李莹, 曲晓辉. 基于机器学习的公司违规预测研究[J]. 财务研究, 2022(4): 54-66. |
| Li Y, Qu X H. Corporate fraud prediction based on machine learning[J]. Finance Research, 2022(4): 54-66. | |
| [25] | Brown I, Mues C. An experimental comparison of classification algorithms for imbalanced credit scoring data sets[J]. Expert Systems with Applications, 2012, 39(3): 3446-3453. |
| [26] | Liu W, Fan H, Xia M. Credit scoring based on tree-enhanced gradient boosting decision trees[J]. Expert Systems with Applications, 2022, 189: 116034. |
| [27] | Liu W, Fan H, Xia M. Step-wise multi-grained augmented gradient boosting decision trees for credit scoring[J]. Engineering Applications of Artificial Intelligence, 2021, 97: 104036. |
| [28] | Khanna V, Kim E H, Lu Y. CEO connectedness and corporate fraud[J]. The Journal of Finance, 2015, 70(3): 1203-1252. |
| [29] | Denis D J, Hanouna P, Sarin A. Is there a dark side to incentive compensation?[J]. Journal of Corporate Finance, 2006, 12(3): 467-488. |
| [30] | Cornett M M, Marcus A J, Tehranian H. Corporate governance and pay-for-performance: The impact of earnings management[J]. Journal of Financial Economics, 2008, 87(2): 357-373. |
| [31] | Bao Y, Ke B, Li B, et al. Detecting accounting fraud in publicly traded U.S. firms using a machine learning approach[J]. Journal of Accounting Research, 2020, 58(1): 199-235. |
| [32] | Dechow P M, Ge W, Larson C R, et al. Predicting material accounting misstatements[J]. Contemporary Accounting Research, 2011, 28(1): 17-82. |
| [33] | 李建平, 孙灏, 常闫芃, 等. 考虑审计要素多重语义关联的财务欺诈识别[J]. 管理科学学报, 2024, 27(3): 58-70. |
| Li J P, Sun H, Chang Y P, et al. Financial statement fraud identification considering the multiple-dimensional semantic associations of auditing elements[J]. Journal of Management Sciences in China, 2024, 27(3): 58-70. | |
| [34] | 袁先智, 周云鹏, 严诚幸, 等. 财务欺诈风险特征筛选框架的建立和应用[J]. 中国管理科学, 2022, 30(3): 43-54. |
| Yuan X Z, Zhou Y P, Yan C X, et al. The framework for the risk feature extraction method on corporate financial fraud George[J]. Chinese Journal of Management Science, 2022, 30(3): 43-54. | |
| [35] | 王爱萍, 马奔, 胡海峰. 公司欺诈问题研究进展[J]. 经济学动态, 2019(2): 115-132. |
| Wang A P, Ma B, Hu H F. The progress of research on corporate fraud[J]. Economic Perspectives, 2019(2): 115-132. | |
| [36] | Wang T Y, Winton A. Competition and corporate fraud waves[C]//Proceedings of the 7th Annual Conference on Empirical Legal Studies, Palo Alto, California, November 9-10, 2012. |
| [37] | 张学勇, 施懿. 基于元学习的财务舞弊识别研究[J]. 管理科学学报, 2023, 26(10): 95-113. |
| Zhang X Y, Shi Y. Financial fraud recognition model based on meta-learning[J]. Journal of Management Sciences in China, 2023, 26(10): 95-113. | |
| [38] | 沈隆, 周颖. 管理层讨论与分析能预示企业违约吗?——基于中国股市的实证分析[J]. 系统管理学报, 2024, 33(2): 441-459. |
| Shen L, Zhou Y. Can management discussion and analysis predict corporate defaults? An empirical analysis based on the Chinese stock market[J]. Journal of Systems & Management, 2024, 33(2): 441-459. | |
| [39] | Lessmann S, Baesens B, Seow H V, et al. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research[J]. European Journal of Operational Research, 2015, 247(1): 124-136. |
| [40] | 周颖, 苏小婷. 基于最优指标组合的企业信用风险预测[J]. 系统管理学报, 2021, 30(5): 817-838. |
| Zhou Y, Su X T. Credit risk prediction of company based on optimal feature set[J]. Journal of Systems & Management, 2021, 30(5): 817-838. | |
| [41] | You J, Zhang B, Zhang L. Who captures the power of the pen?[J]. The Review of Financial Studies, 2018, 31(1): 43-96. |
| [1] | 李国文, 龚羽豪, 李靖宇, 王帅. 信息披露数据异常分布检验:一种财务欺诈检测的新策略[J]. 中国管理科学, 2026, 34(2): 67-78. |
| [2] | 胡丹, 周凌雲, 梁樑. 我国上市公司精准扶贫的农户增收效应研究[J]. 中国管理科学, 2025, 33(4): 12-23. |
| [3] | 胡忠义, 税典程, 吴江. 中国上市公司数字化水平测度与演化研究——来自年报文本的经验证据[J]. 中国管理科学, 2025, 33(4): 36-49. |
| [4] | 许帅, 邵帅, 何贤杰. 业绩说明会前瞻性信息对分析师盈余预测准确性的影响[J]. 中国管理科学, 2025, 33(3): 34-44. |
| [5] | 游万海, 陈森杰, 陈健永, 任英华. “多言寡行”环境责任表现对股价崩盘风险的影响——基于投资者情绪的中介效应[J]. 中国管理科学, 2025, 33(10): 12-23. |
| [6] | 闫达文,李存,迟国泰. 基于混频数据的中国上市公司财务困境动态预测研究[J]. 中国管理科学, 2024, 32(1): 1-12. |
| [7] | 陈艺云, 陈曼莲. 定性文本信息与信用评级:基于年报文本分析的研究[J]. 中国管理科学, 2023, 31(9): 94-104. |
| [8] | 赵宇,黄冰冰,邓元慧. 基于倾向评分匹配的国家双创示范基地内上市公司财务绩效分析[J]. 中国管理科学, 2023, 31(10): 136-145. |
| [9] | 陈艺云. 基于信息披露文本的上市公司财务困境预测:以中文年报管理层讨论与分析为样本的研究[J]. 中国管理科学, 2019, 27(7): 23-34. |
| [10] | 刘中文, 段升森, 于艺浩. 基于效率视角的上市公司股权激励工具选择研究[J]. 中国管理科学, 2019, 27(11): 31-38. |
| [11] | 高惠, 韦玉龙, 刘阳. IPO发行制度与信息披露质量——基于保荐制实施与否的比较[J]. 中国管理科学, 2015, 23(5): 23-31. |
| [12] | 马健, 刘志新, 张力健. 双重异质信念下中国上市公司融资决策研究 [J]. 中国管理科学, 2012, (2): 50-56. |
| [13] | 陈其安, 方彩霞, 肖映红. 基于上市公司高管人员过度自信的股利分配决策模型研究[J]. 中国管理科学, 2010, 18(3): 174-184. |
| [14] | 曹裕, 陈晓红, 万光羽. 基于企业生命周期的上市公司融资结构研究[J]. 中国管理科学, 2009, 17(3): 150-158. |
| [15] | 李万福, 叶阿忠. 中国上市公司融资结构的宏观因素分析[J]. 中国管理科学, 2007, 15(6): 26-32. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||