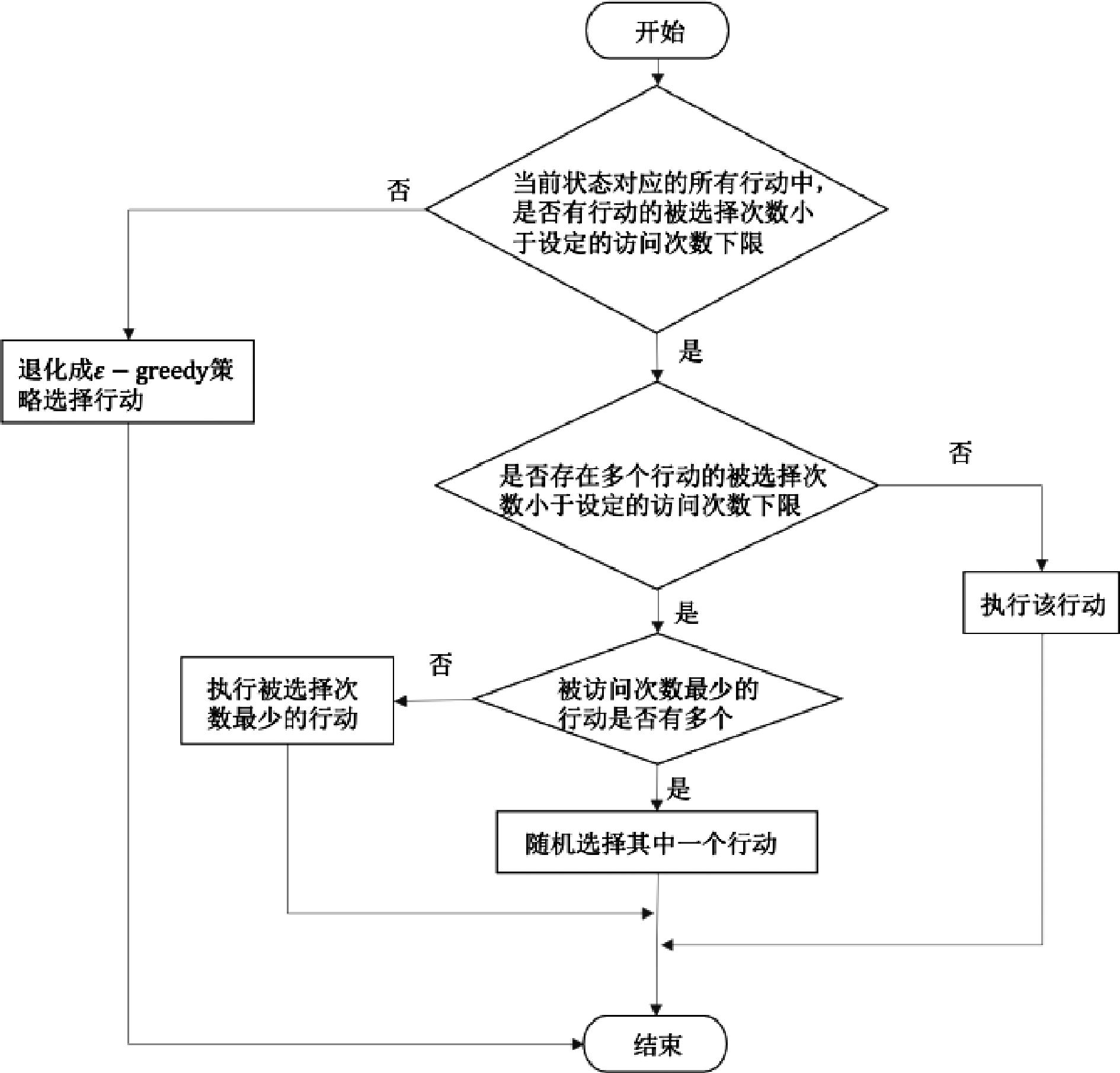
| [1] |
Charpentier A, Élie R, Remlinger C. Reinforcement learning in economics and finance[J]. Computational Economics, 2023, 62(1): 425-462.
|
| [2] |
Dogan I, Güner A R. A reinforcement learning approach to competitive ordering and pricing problem[J]. Expert Systems, 2015, 32(1): 39-48.
|
| [3] |
Calvano E, Calzolari G, Denicolò V, et al. Artificial intelligence, algorithmic pricing, and collusion[J]. The American Economic Review, 2020, 110(10): 3267-3297.
|
| [4] |
Littman M L. Markov games as a framework for multi-agent reinforcement learning[C]//Proceedings of the Eleventh International Conference, Rutgers University, New MORGA Brunswick, NJ, July 10-13, 1994: 157-163.
|
| [5] |
Hu J, Wellman M P. Nash q-learning for general-sum stochastic games[J]. Journal of Machine Learning Research, 2003, 4: 1039-1069.
|
| [6] |
Sridharan M, Tesauro G. Multi-agent Q-learning and regression trees for automated pricing decisions[M]// Parsons S, Gmytrasiewicz P, Wooldridge M. Game Theory and Decision Theory in Agent-Based Systems. Boston,MA:Springer US,2002:217-234.
|
| [7] |
Ye M A, Tianqing C, Wenhui F. A single-task and multi-decision evolutionary game model based on multi-agent reinforcement learning[J]. Journal of Systems Engineering and Electronics,2021,32(3): 642-657.
|
| [8] |
dos Santos Mignon A, de Azevedo da Rocha R L. An adaptive implementation of ε-greedy in reinforcement learning[J]. Procedia Computer Science, 2017, 109: 1146-1151.
|
| [9] |
Tokic M. Adaptive ε-greedy exploration in reinforcement learning based on value differences[C]//Proceedings of Annual Conference on Artificial Intelligence, Berlin, Heidelberg, September 21-24 , Springer Berlin Heidelberg, 2010: 203-210.
|
| [10] |
Sutton R S, Barto A G. Reinforcement Learning: An Introduction[M]. 2nd ed. Cambridge, MA: MIT Press, 2018.
|
| [11] |
Angelopoulos G, Metafas D. Forced ε-greedy, an expansion to the ε-greedy action selection method[C]//Proceedings of the 1st International Conference on Novelties in Intelligent Digital Systems, Athens, Greece, September 30-October 1 , IOS Press, 2021: 12-20.
|
| [12] |
Dabney W, Ostrovski G, Barreto A. Temporallyextended ε-greedy exploration [EB/OL].(2020-06-02)[2023-01-30]. .
|
| [13] |
Gimelfarb M, Sanner S, Lee C G. ε-BMC:A Bayesian ensemble approach to epsilon-greedy exploration in model-free reinforcement learning[EB/OL].(2020-07-02)[2023-01-30]..
|
| [14] |
Vidhate D A, Kulkarni P. A framework for dynamic decision making by multi-agent cooperative fault pair algorithm (MCFPA) in retail shop application[C]//Proceedings of Information and Communication Technology for Intelligent Systems, Singapore, April 6-7 , Springer Singapore, 2018: 693-703.
|
| [15] |
Li X, Qin X, Zang C, et al. Pricing scheme based Nash Q-learning load control in smart grids[C]// Proceedings of 2013 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, May 25-27, IEEE, 2013: 5198-5202.
|
| [16] |
Lopez V G, Lewis F L, Liu M, et al. Game-theoretic lane-changing decision making and payoff learning for autonomous vehicles[J]. IEEE Transactions on Vehicular Technology, 2022, 71(4): 3609-3620.
|
| [17] |
Zhou X, Kuang D, Zhao W, et al. Lane-changing decision method based Nash Q-learning with considering the interaction of surrounding vehicles[J]. IET Intelligent Transport Systems, 2020, 14(14): 2064-2072.
|
| [18] |
Ma M, Zhu A, Guo S, et al. Intelligent network selection algorithm for multiservice users in 5G heterogeneous network system: Nash Q-learning method[J]. IEEE Internet of Things Journal, 2021, 8(15): 11877-11890.
|
| [19] |
丁雨, 李晨凯, 韩会梅, 等. 基于5G无人机通信的多智能体异构网络选择方法[J]. 电信科学, 2022, 38(8): 28-36.
|
|
Ding Y, Li C K, Han H M, et al. Multi-agent heterogeneous network selection method based on 5G UAV communication[J]. Telecommunications Science, 2022, 38(8): 28-36.
|
| [20] |
Guo J, Harmati I. Evaluating semi-cooperative Nash/Stackelberg Q-learning for traffic routes plan in a single intersection[J]. Control Engineering Practice, 2020, 102: 104525.
|
| [21] |
Yang L, Sun Q, Ma D, et al. Nash Q-learning based equilibrium transfer for integrated energy management game with We-Energy[J]. Neurocomputing, 2020, 396: 216-223.
|
| [22] |
闫雪飞, 李新明, 刘东, 等. 基于Nash-Q的网络信息体系对抗仿真技术[J]. 系统工程与电子技术, 2018, 40(1): 217-224.
|
|
Yan X F, Li X M, Liu D, et al. Confrontation simulation for network information system-of-systems based on Nash-Q[J]. Systems Engineering and Electronics, 2018, 40(1): 217-224.
|
| [23] |
Zhang Y, Gan R, Shao J, et al. Path selection with Nash Q-learning for remote state estimation over multihop relay network[J]. International Journal of Robust and Nonlinear Control, 2020, 30(11): 4331-4344.
|
| [24] |
Wang J, Cao L, Chen X, et al. General proof of convergence of the Nash-q-learning algorithm[J]. Fractals, 2022, 30: 2250027.
|
| [25] |
Zhuang Y, Chen X, Gao Y, et al. Accelerating Nash Q-learning with graphical game representation and equilibrium solving[C]//Proceedings of 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, November 4-6, IEEE, 2020: 939-946.
|
| [26] |
Ghazanfari B, Mozayani N. Enhancing Nash Q-learning and Team Q-learning mechanisms by using bottlenecks[J]. Journal of Intelligent & Fuzzy Systems, 2014, 26(6): 2771-2783.
|
| [27] |
Watkins C J C H, Dayan P. Q-learning[J]. Machine Learning, 1992, 8(3): 279-292.
|
| [28] |
Mitchell T M. Does machine learning really work?[J]. AI Magazine, 1997, 18(3): 11-20.
|
| [29] |
Chang Y H, Ho T, Kaelbling L. All learning is local: Multi-agent learning in global reward games[J]. Advances in Neural Information Processing Systems, 2003, 16.
|
| [30] |
Laurent F, Schneider M, Scheller C, et al. Flatland competition 2020: MAPF and MARL for efficient train coordination on a grid world[C]//Proceedings of NeurIPS 2020 Competition and Demonstration Track, Online, December 6-12 , PMLR, 2021: 275-301.
|
| [31] |
Greenwald A, Hall K, Serrano R. Correlated Q-learning[C]//Proceedings of the 20th ICML, Washington, DC USA, August 21 , AAAI Press, 2003, 3: 242-249.
|
| [32] |
Littman M L. Friend-or-foe Q-learning in general-sum games[C]//Proceedings of the 18th ICML, San Francisco, United States, June 28-July 1 , Morgan Kaufmann, 2001: 322-328.
|
 ), 李璨
), 李璨