主管:中国科学院
主办:中国优选法统筹法与经济数学研究会
中国科学院科技战略咨询研究院
主办:中国优选法统筹法与经济数学研究会
中国科学院科技战略咨询研究院
中国管理科学 ›› 2026, Vol. 34 ›› Issue (2): 67-78.doi: 10.16381/j.cnki.issn1003-207x.2023.1719cstr: 32146.14.j.cnki.issn1003-207x.2023.1719
李国文1, 龚羽豪2, 李靖宇3( ), 王帅1
), 王帅1
收稿日期:2023-10-25
修回日期:2024-09-16
出版日期:2026-02-25
发布日期:2026-02-04
通讯作者:
李靖宇
E-mail:lijy@bjut.edu.cn
基金资助:
Guowen Li1, Yuhao Gong2, Jingyu Li3(), Shuai Wang1
Received:2023-10-25
Revised:2024-09-16
Online:2026-02-25
Published:2026-02-04
Contact:
Jingyu Li
E-mail:lijy@bjut.edu.cn
摘要:
财务欺诈会对金融市场造成重大损害,传统基于财务指标的方法难以精准识别欺诈行为。在财务欺诈情境下,管理层对信息披露内容进行了篡改,公司原本的信息披露特征会发生偏离。本文研究如何刻画这种偏离,进而提出了一种基于信息披露数据异常分布特征的财务欺诈检测新策略。基于2010—2020年中国市场数据,本文证实了在自然情况下,信息披露的数字和文本分布特征在总体和行业上分别符合本福特定律和齐普夫定律;而数据分布相对这些定律存在偏离的公司,更可能存在实施财务欺诈的情况;更进一步,数据偏离规律的程度越大,存在欺诈的可能性越高。采用经典的财务欺诈检测模型,研究同时证实了考虑信息披露异常分布特征能够显著提升欺诈检测效果。
中图分类号:
李国文,龚羽豪,李靖宇, 等. 信息披露数据异常分布检验:一种财务欺诈检测的新策略[J]. 中国管理科学, 2026, 34(2): 67-78.
Guowen Li,Yuhao Gong,Jingyu Li, et al. Test for Anomalous Distribution of Information Disclosure: A New Strategy for Financial Fraud Detection[J]. Chinese Journal of Management Science, 2026, 34(2): 67-78.
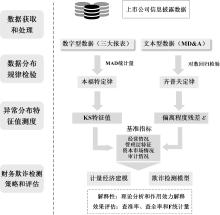
图1
研究总体设计"

表1
本福特定律检验结果(MAD检验)"
| 行业 | 样本数 | 行业 | 样本数 | ||
|---|---|---|---|---|---|
| 交通运输 | 1226 | 0.00081 | 煤炭 | 431 | 0.00239 |
| 传媒 | 1390 | 0.00130 | 环保 | 782 | 0.00184 |
| 公用事业 | 1143 | 0.00110 | 电力设备 | 2111 | 0.00095 |
| 农林牧渔 | 904 | 0.00160 | 电子 | 2224 | 0.00078 |
| 医药生物 | 3110 | 0.00039 | 石油石化 | 483 | 0.00168 |
| 商贸零售 | 1018 | 0.00083 | 社会服务 | 650 | 0.00181 |
| 国防军工 | 901 | 0.00164 | 纺织服饰 | 918 | 0.00216 |
| 基础化工 | 2546 | 0.00082 | 综合 | 327 | 0.00155 |
| 家用电器 | 669 | 0.00143 | 美容护理 | 152 | 0.00420 |
| 建筑材料 | 760 | 0.00097 | 计算机 | 2115 | 0.00160 |
| 建筑装饰 | 1096 | 0.00079 | 轻工制造 | 919 | 0.00233 |
| 房地产 | 1454 | 0.00099 | 通信 | 837 | 0.00100 |
| 有色金属 | 1157 | 0.00155 | 钢铁 | 453 | 0.00208 |
| 机械设备 | 3045 | 0.00095 | 食品饮料 | 934 | 0.00140 |
| 汽车 | 1741 | 0.00061 | 所有公司 | 35496 | 0.00052 |
表2
本福特定律检验结果(KS检验)"
| 行业 | 样本数 | 百分比 | 行业 | 样本数 | 百分比 |
|---|---|---|---|---|---|
| 交通运输 | 1226 | 89.89 | 煤炭 | 431 | 90.49 |
| 传媒 | 1390 | 84.89 | 环保 | 782 | 86.32 |
| 公用事业 | 1143 | 86.35 | 电力设备 | 2111 | 87.87 |
| 农林牧渔 | 904 | 86.95 | 电子 | 2224 | 87.1 |
| 医药生物 | 3110 | 86.4 | 石油石化 | 483 | 87.78 |
| 商贸零售 | 1018 | 88.51 | 社会服务 | 650 | 87.85 |
| 国防军工 | 901 | 86.68 | 纺织服饰 | 918 | 84.10 |
| 基础化工 | 2546 | 84.17 | 综合 | 327 | 89.30 |
| 家用电器 | 669 | 82.36 | 美容护理 | 152 | 80.92 |
| 建筑材料 | 760 | 87.11 | 计算机 | 2115 | 86.05 |
| 建筑装饰 | 1096 | 86.95 | 轻工制造 | 919 | 82.48 |
| 房地产 | 1454 | 90.10 | 通信 | 837 | 86.02 |
| 有色金属 | 1157 | 85.57 | 钢铁 | 453 | 85.21 |
| 机械设备 | 3045 | 85.52 | 食品饮料 | 934 | 84.15 |
| 汽车 | 1741 | 86.73 | 所有公司 | 35496 | 86.36 |
表3
齐普夫定律检验结果"
| 行业 | 词语数 | 系数 | 行业 | 词语数 | 系数 | ||
|---|---|---|---|---|---|---|---|
| 交通运输 | 191 | -0.82*** | 0.973 | 煤炭 | 284 | -0.75*** | 0.979 |
| 传媒 | 206 | -0.82*** | 0.973 | 环保 | 196 | -0.77*** | 0.974 |
| 公用事业 | 173 | -0.84*** | 0.969 | 电力设备 | 265 | -0.86*** | 0.974 |
| 农林牧渔 | 150 | -0.78*** | 0.977 | 电子 | 231 | -0.86*** | 0.975 |
| 医药生物 | 551 | -0.96*** | 0.971 | 石油石化 | 661 | -0.72*** | 0.969 |
| 商贸零售 | 149 | -0.78*** | 0.972 | 社会服务 | 101 | -0.74*** | 0.976 |
| 国防军工 | 89 | -0.76*** | 0.977 | 纺织服饰 | 141 | -0.80*** | 0.976 |
| 基础化工 | 413 | -0.89*** | 0.976 | 综合 | 254 | -0.69*** | 0.988 |
| 家用电器 | 172 | -0.70*** | 0.979 | 计算机 | 218 | -0.88*** | 0.970 |
| 建筑材料 | 104 | -0.77** | 0.975 | 轻工制造 | 159 | -0.81*** | 0.974 |
| 建筑装饰 | 220 | -0.84*** | 0.978 | 通信 | 101 | -0.79*** | 0.974 |
| 房地产 | 268 | -0.85*** | 0.979 | 钢铁 | 243 | -0.68*** | 0.975 |
| 有色金属 | 176 | -0.83*** | 0.968 | 食品饮料 | 138 | -0.78*** | 0.977 |
| 机械设备 | 297 | -0.88*** | 0.973 | 所有公司 | 4910 | -1.122*** | 0.975 |
| 汽车 | 152 | -0.81*** | 0.976 |
表4
数字异常分布特征检验结果"
| 申万行业 | 非欺诈组 | 欺诈组 | 申万行业 | 非欺诈组 | 欺诈组 |
|---|---|---|---|---|---|
| 交通运输 | 86.27 | 76.92 | 煤炭 | 90.16 | 81.82 |
| 传媒 | 88.72 | 88.33 | 环保 | 92.41 | 84.62 |
| 公用事业 | 87.41 | 83.33 | 电力设备 | 91.62 | 82.56 |
| 农林牧渔 | 88.46 | 89.19 | 电子 | 90.12 | 82.22 |
| 医药生物 | 88.92 | 87.93 | 石油石化 | 85.37 | 85.00 |
| 商贸零售 | 91.45 | 85.19 | 社会服务 | 91.80 | 78.57 |
| 国防军工 | 92.96 | 80.00 | 纺织服饰 | 93.20 | 77.42 |
| 基础化工 | 88.34 | 86.89 | 综合 | 86.21 | 76.47 |
| 家用电器 | 94.00 | 80.00 | 计算机 | 95.63 | 86.05 |
| 建筑材料 | 86.84 | 90.91 | 轻工制造 | 89.84 | 96.00 |
| 建筑装饰 | 92.94 | 85.71 | 通信 | 98.36 | 72.41 |
| 房地产 | 92.99 | 84.09 | 钢铁 | 91.11 | 87.50 |
| 有色金属 | 88.24 | 87.50 | 食品饮料 | 91.30 | 83.87 |
| 机械设备 | 87.78 | 82.26 | 所有公司 | 89.94 | 84.49 |
| 汽车 | 79.78 | 84.62 |
表5
变量描述性统计和均值差异"
| 变量 | 样本数 | 欺诈公司 | 非欺诈公司 | 均值差异 | ||
|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | |||
| 4627 | 0.84 | 0.36 | 0.90 | 0.30 | -0.06*** | |
| 4627 | 0.31 | 0.05 | 0.24 | 0.04 | 0.07*** | |
| 公司规模 | 4627 | 9.73 | 0.50 | 9.98 | 0.62 | -0.25*** |
| 资产负债率 | 4627 | 0.50 | 0.21 | 0.47 | 0.20 | 0.03*** |
| 总应计项 | 4627 | -0.02 | 0.29 | -0.02 | 0.10 | 0.00 |
| 其他应收款比率 | 4627 | 0.03 | 0.05 | 0.02 | 0.03 | 0.01*** |
| 是否亏损 | 4627 | 0.24 | 0.43 | 0.10 | 0.30 | 0.14*** |
| 应收账款周转率 | 4627 | 0.60 | 0.52 | 0.66 | 0.52 | -0.06*** |
| 折旧率指数 | 4627 | 0.90 | 4.79 | 0.90 | 7.27 | 0.00 |
| ROA | 4627 | 0.01 | 0.18 | 0.04 | 0.07 | -0.03*** |
| ROA增长率 | 4627 | -1.98 | 13.48 | -0.28 | 31.49 | -1.70* |
| 股权集中度 | 4627 | 0.13 | 0.10 | 0.17 | 0.12 | -0.03*** |
| 机构投资者持股比例 | 4627 | 0.37 | 0.23 | 0.45 | 0.23 | -0.07*** |
| 独立董事比例 | 4627 | 0.37 | 0.05 | 0.38 | 0.06 | 0.01** |
| Z指数 | 4627 | 7.37 | 12.19 | 7.64 | 14.74 | -0.26 |
| 董事长与总经理兼任 | 4627 | 0.28 | 0.45 | 0.27 | 0.44 | 0.01 |
| 股票月换手波动率 | 4627 | -0.02 | 0.43 | -0.06 | 0.47 | 0.04** |
| 账面市值比 | 4627 | 0.69 | 0.24 | 0.75 | 0.25 | -0.06*** |
| 股市周期 | 4627 | 0.31 | 0.46 | 0.29 | 0.45 | 0.03* |
| 特别处理ST | 4627 | 0.11 | 0.43 | 0.03 | 0.25 | 0.08*** |
| 审计意见 | 4627 | 0.84 | 0.37 | 0.97 | 0.17 | -0.13*** |
| 审计公司资质 | 4627 | 0.04 | 0.19 | 0.09 | 0.29 | -0.05*** |

图2
代表性行业关键词云图"

表6
信息披露异常分布特征与财务欺诈回归结果"
| 变量 | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| 常数项 | 0.508 | 1.170 | 2.501 | -0.019 |
| -0.512** | -0.498*** | -0.732* | -0.467*** | |
| 104.021*** | 36.131*** | 53.948*** | 39.413*** | |
| 公司规模 | 0.444*** | -0.772*** | -2.559* | -0.887*** |
| 资产负债率 | 3.935*** | 1.081*** | 2.187 | 0.483 |
| 总应计项 | 2.083* | 0.823* | 0.217 | 0.337* |
| 其他应收款比率 | 51.152*** | 3.903*** | 12.374*** | 3.898*** |
| 是否亏损 | 1.041* | 0.0528 | -0.058* | 0.321** |
| 应收账款周转率 | 0.875 | -0.235** | -0.858 | -0.326*** |
| 折旧率指数 | 0.999 | -0.004 | -0.749** | -0.008 |
| ROA | 0.460 | -0.594 | -2.398 | -0.346 |
| ROA增长率 | 1.000 | 0.001 | -0.013 | 0.001 |
| 股权集中度 | 0.660 | -1.008* | 2.421 | -1.917*** |
| 机构投资者持股比例 | 0.948 | -0.036 | 0.145 | 0.430 |
| 独立董事比例 | 0.604 | -0.512 | -1.658 | 0.887 |
| Z指数 | 1.009*** | 0.009*** | 0.012* | 0.009** |
| 董事长与总经理兼任 | 0.814** | -0.168 | 0.381 | -0.084 |
| 股票月换手波动率 | 0.995 | -0.031 | 0.672* | 0.127 |
| 账面市值比 | 0.752 | -0.662*** | 0.514 | 0.132 |
| 股市周期 | 0.980 | -0.041 | - | - |
| 特别处理ST | 0.869 | -0.170 | -0.186 | 0.033 |
| 审计意见 | 0.324*** | -1.125*** | 1.125* | -1.289*** |
| 审计公司资质 | 0.881 | -0.166 | 1.436 | -0.554** |
| 固定年份 | 否 | 否 | 是 | 是 |
| 固定行业 | 否 | 是 | 否 | 是 |
| Pseudo | 0.3520 | 0.3886 | 0.4775 | 0.5133 |
| 1717.40*** | 1886.26*** | 1724.24*** | 2504.12*** |
表7
基于信息披露数据异常分布的财务欺诈检测效果"
| 检测模型 | 比较基准 | 最大提升 | |||
|---|---|---|---|---|---|
| 面板A:准确率比较结果 | |||||
| 逻辑回归 | 0.6177 | 0.6274*** | 0.7934*** | +0.1784 | |
| 支持向量机 | 0.7437 | 0.7463** | 0.8260*** | +0.0863 | |
| 随机森林 | 0.7431 | 0.7442 | 0.8564*** | +0.1140 | |
| 长短期记忆网络 | 0.6882 | 0.6946*** | 0.6904*** | +0.1383 | |
| 循环神经网络 | 0.6298 | 0.6396* | 0.8103*** | +0.1849 | |
| RUSBoost | 0.6548 | 0.6545 | 0.7702*** | +0.1233 | |
| 面板B:查准率比较结果 | |||||
| 逻辑回归 | 0.6396 | 0.6522*** | 0.8071*** | +0.1728 | |
| 支持向量机 | 0.6919 | 0.6903 | 0.8162*** | +0.1316 | |
| 随机森林 | 0.7553 | 0.7538 | 0.8648*** | +0.1117 | |
| 长短期记忆网络 | 0.7154 | 0.7189* | 0.7134 | +0.1154 | |
| 循环神经网络 | 0.6644 | 0.6682 | 0.8287*** | +0.1695 | |
| RUSBoost | 0.6686 | 0.6675 | 0.7888*** | +0.1240 | |
| 面板C:查全率比较结果 | |||||
| 逻辑回归 | 0.5480 | 0.5546*** | 0.7714*** | +0.2242 | |
| 支持向量机 | 0.8836 | 0.8429*** | 0.8416*** | +0.0136 | |
| 随机森林 | 0.7222 | 0.7280** | 0.8427*** | +0.1251 | |
| 长短期记忆网络 | 0.6277 | 0.6416*** | 0.6398*** | +0.1935 | |
| 循环神经网络 | 0.5323 | 0.5563* | 0.7838*** | +0.2551 | |
| RUSBoost | 0.6139 | 0.6156 | 0.7377*** | +0.1390 | |
| 面板D:F1度量比较 | |||||
| 逻辑回归 | 0.5887 | 0.5979*** | 0.7889*** | +0.2023 | |
| 支持向量机 | 0.7747 | 0.7792** | 0.8289*** | +0.0572 | |
| 随机森林 | 0.7376 | 0.7399* | 0.8544** | +0.1181 | |
| 长短期记忆网络 | 0.6679 | 0.6772*** | 0.6736*** | +0.1577 | |
| 循环神经网络 | 0.5818 | 0.6034** | 0.8052*** | +0.2278 | |
| RUSBoost | 0.6393 | 0.6394* | 0.7617*** | +0.1322 | |

图3
不同模型情境下的指标贡献情况"

| [1] | Li G, Wang S, Feng Y. Making differences work: Financial fraud detection based on multi-subject perceptions[J]. Emerging Markets Review,2024, 60: 101134. |
| [2] | Beasley M S, Hermanson D R, Carcello J V, et al. Fraudulent financial reporting: 1998-2007: An analysis of US public companies[R].Working Paper,Committee of Sponsoring Organizations of the Treadway Commission, 2010. |
| [3] | ACFE. Report to the nation: 2020 global study on occupation fraud and abuse[R].Working Paper, ACFE Global Headquarters, 2020. |
| [4] | Zhu X, Ao X, Qin Z, et al. Intelligent financial fraud detection practices in post-pandemic era[J]. The Innovation, 2021, 2(4): 100176. |
| [5] | Beneish M D. The detection of earnings manipulation[J]. Financial Analysts Journal, 1999, 55(5): 24-36. |
| [6] | Jones J J. Earnings management during import relief investigations[J].Journal of Accounting Research, 1991, 29(2): 193-228. |
| [7] | Dechow P M, Ge W, Larson C R, et al. Predicting material accounting misstatements[J]. Contemporary Accounting Research, 2011, 28(1): 17-82. |
| [8] | Chen G, Firth M, Gao D N, et al. Ownership structure, corporate governance, and fraud: Evidence from China[J]. Journal of Corporate Finance, 2006, 12(3): 424-448. |
| [9] | 温石刚, 朱晓谦, 李建平. 公司财务欺诈行为的同群效应: 基于连锁董事网络社团的研究[J]. 工程管理科技前沿, 2023, 42(3): 20-28. |
| Wen S G, Zhu X Q, Li J P. A study on the peer effect of financial statement fraud based on the communities of interlocking director networks[J]. Frontiers of Science and Technology of Engineering Management, 2023, 42(3): 20-28. | |
| [10] | DeFond M L, Subramanyam K R. Auditor changes and discretionary accruals[J]. Journal of Accounting and Economics, 1998, 25(1): 35-67. |
| [11] | Erickson M, Hanlon M, Maydew E L. Is there a link between executive equity incentives and accounting fraud?[J]. Journal of Accounting Research, 2006, 44(1): 113-143. |
| [12] | Li J, Chang Y, Wang Y, et al. Tracking down financial statement fraud by analyzing the supplier-customer relationship network[J]. Computers & Industrial Engineering, 2023, 178: 109118. |
| [13] | Dechow P M, Sloan R G, Sweeney A P. Detecting earnings management[J]. The Accounting Review, 1995, 70(2): 193-225. |
| [14] | Liu R, Huang J, Zhang Z. Tracking disclosure change trajectories for financial fraud detection[J]. Production and Operations Management, 2023, 32(2): 584-602. |
| [15] | Amiram D, Bozanic Z, Rouen E. Financial statement errors: Evidence from the distributional properties of financial statement numbers[J]. Review of Accounting Studies, 2015, 20(4): 1540-1593. |
| [16] | Dechow P, Ge W, Schrand C. Understanding earnings quality: A review of the proxies, their determinants and their consequences[J]. Journal of Accounting and Economics, 2010, 50(2-3): 344-401. |
| [17] | 钱苹, 罗玫. 中国上市公司财务造假预测模型[J]. 会计研究, 2015(7): 18-25+96. |
| Qian P, Luo M. Predicting accounting fraud in China[J]. Accounting Research, 2015(7): 18-25+96. | |
| [18] | Dong W, Liao S, Zhang Z. Leveraging financial social media data for corporate fraud detection[J]. Journal of Management Information Systems, 2018, 35(2): 461-487. |
| [19] | Hill T P. A statistical derivation of the significant-digit law[J]. Statistical Science, 1995, 10(4): 354-363. |
| [20] | Michalski T, Stoltz G. Do countries falsify economic data strategically? some evidence that they might[J]. The Review of Economics and Statistics, 2013, 95(2): 591-616. |
| [21] | Nigrini M J, Mittermaier L J. The use of Benford's law as an aid in analytical procedures[J]. Auditing, 1997, 16(2): 52-67. |
| [22] | Zipf B G K. Human Behavior and the principle of least effort: An introduction to human ecology[M]. Mansfield Centre, Conn.: Martino Pub, 2012. |
| [23] | Huang S M, Yen D C, Yang L W, et al. An investigation of Zipf’s law for fraud detection[J]. Decision Support Systems, 2008, 46(1): 70-83. |
| [24] | Iorliam A, Ho A T S, Poh N, et al. Data forensic techniques using Benford’s law and Zipf’s law for keystroke dynamics[C]//Processdings of the 3rd International Workshop on Biometrics and Forensics (IWBF 2015),Gjovik, Norway, March 3-4, IEEE, 2015: 1-6. |
| [25] | Chakravarthy J, DeHaan E, Rajgopal S. Reputation repair after a serious restatement[J]. The Accounting Review, 2014, 89(4): 1329-1363. |
| [26] | 王鲁平, 陈羿. 管理舞弊的形成机理及治理对策研究[J]. 管理工程学报, 2018, 32(1): 107-116. |
| Wang L P, Chen Y. Research of formation mechanism and countermeasure of management fraud[J]. Journal of Industrial Engineering and Engineering Management, 2018, 32(1): 107-116. | |
| [27] | Dyck A, Morse A, Zingales L. How pervasive is corporate fraud?[J]. Review of Accounting Studies, 2024, 29(1): 736-769. |
| [28] | Brazel J F, Jones K L, Zimbelman M F. Using nonfinancial measures to assess fraud risk[J]. Journal of Accounting Research, 2009, 47(5): 1135-1166. |
| [29] | Lin C C, Chiu A A, Huang S Y, et al. Detecting the financial statement fraud: The analysis of the differences between data mining techniques and experts’ judgments[J].Knowledge-Based Systems,2015, 89: 459-470. |
| [30] | 李建平, 孙灏, 常闫芃, 等. 考虑审计要素多重语义关联的财务欺诈识别[J]. 管理科学学报, 2024, 27(3): 58-70. |
| Li J P, Sun H, Chang Y P, et al. Financial statement fraud identification considering the multiple-dimensional semantic associations of auditing elements[J]. Journal of Management Sciences in China, 2024, 27(3): 58-70. | |
| [31] | Goel S, Gangolly J. Beyond the numbers: Mining the annual reports for hidden cues indicative of financial statement fraud[J]. Intelligent Systems in Accounting, Finance and Management, 2012, 19(2): 75-89. |
| [32] | Purda L, Skillicorn D. Accounting variables, deception, and a bag of words: Assessing the tools of fraud detection[J]. Contemporary Accounting Research, 2015, 32(3): 1193-1223. |
| [33] | Hajek P, Henriques R. Mining corporate annual reports for intelligent detection of financial statement fraud–A comparative study of machine learning methods[J]. Knowledge-Based Systems, 2017, 128: 139-152. |
| [34] | Larcker D F, Zakolyukina A A. Detecting deceptive discussions in conference calls[J]. Journal of Accounting Research, 2012, 50(2): 495-540. |
| [35] | Xu X, Xiong F, An Z. Using machine learning to predict corporate fraud: Evidence based on the GONE framework[J]. Journal of Business Ethics, 2023, 186(1): 137-158. |
| [36] | Li J, Li N, Xia T, et al. Textual analysis and detection of financial fraud: Evidence from Chinese manufacturing firms[J]. Economic Modelling, 2023, 126: 106428. |
| [37] | Cecchini M, Aytug H, Koehler G J, et al. Detecting management fraud in public companies[J]. Management Science, 2010, 56(7): 1146-1160. |
| [38] | Bertomeu J, Cheynel E, Floyd E, et al. Using machine learning to detect misstatements[J]. Review of Accounting Studies, 2021, 26(2): 468-519. |
| [39] | 袁先智, 周云鹏, 严诚幸, 等. 财务欺诈风险特征筛选框架的建立和应用[J]. 中国管理科学, 2022, 30(3): 43-54. |
| Yuan X Z, Zhou Y P, Yan C X, et al. The framework for the risk feature extraction method on corporate financial fraud George[J]. Chinese Journal of Management Science, 2022, 30(3): 43-54. | |
| [40] | Achakzai M A K, Peng J. Detecting financial statement fraud using dynamic ensemble machine learning[J]. International Review of Financial Analysis, 2023, 89: 102827. |
| [41] | Hoberg G, Lewis C. Do fraudulent firms produce abnormal disclosure?[J]. Journal of Corporate Finance, 2017, 43: 58-85. |
| [42] | 杨贵军, 孙玲莉, 周亚梦, 等. 基于修正Benford律的财务危机预警Logistic模型及其应用[J]. 数理统计与管理, 2021, 40(4): 585-595. |
| Yang G J, Sun L L, Zhou Y M, et al. Financial early warning logistic model based on corrected benford’s law and its application[J]. Journal of Applied Statistics and Management, 2021, 40(4): 585-595. | |
| [43] | 赵子夜, 杨庆, 杨楠. 言多必失? 管理层报告的样板化及其经济后果[J]. 管理科学学报, 2019, 22(3): 53-70. |
| Zhao Z Y, Yang Q, Yang N. The less said the better? Economic consequences of textual similarity in man-agement discussion and analysis[J]. Journal of Management Sciences in China, 2019, 22(3): 53-70. | |
| [44] | Li F. The information content of forward-looking statements in corporate filings—a Naïve Bayesian machine learning approach[J]. Journal of Accounting Research, 2010, 48(5): 1049-1102. |
| [45] | 薛爽, 肖泽忠, 潘妙丽. 管理层讨论与分析是否提供了有用信息?——基于亏损上市公司的实证探索[J]. 管理世界, 2010, 26(5): 130-140. |
| Xue S, Xiao Z Z, Pan M L. Did the management discussion and analysis provide useful information?-Empirical exploration based on loss-making listed companies[J]. Journal of Management World, 2010, 26(5): 130-140. | |
| [46] | Lo K, Ramos F, Rogo R. Earnings management and annual report readability[J]. Journal of Accounting and Economics, 2017, 63(1): 1-25. |
| [47] | Benford F. The law of anomalous numbers[J]. Proceedings of the American Philosophical Society, 1938, 78(4): 551-572. |
| [48] | Joos M, Zipf G K. The psycho-biology of language[J]. Language, 1936, 12(3): 196-210. |
| [49] | Urzúa C M. A simple and efficient test for Zipf’s law[J]. Economics Letters, 2000, 66(3): 257-260. |
| [50] | Pao M L. Automatic text analysis based on transition phenomena of word occurrences[J]. Journal of the American Society for Information Science, 1978, 29(3): 121-124. |
| [51] | Loughran T, McDonald B. Textual analysis in accounting and finance: A survey[J]. Journal of Accounting Research, 2016, 54(4): 1187-1230. |
| [52] | Loughran T, McDonald B. When is a liability not a liability? textual analysis, dictionaries, and 10-ks[J]. The Journal of Finance, 2011, 66(1): 35-65. |
| [53] | Jiang F, Lee J, Martin X, et al. Manager sentiment and stock returns[J]. Journal of Financial Economics, 2019, 132(1): 126-149. |
| [54] | 郝俊, 李建平, 冯倩倩, 等. 基于溢出效应的金融危机早期预警方法研究[J]. 中国管理科学, 2023, 31(4): 35-45. |
| Hao J, Li J P, Feng Q Q, et al. Early warning of financial crisis based on the spillover effects[J]. Chinese Journal of Management Science, 2023, 31(4): 35-45. | |
| [55] | Lundberg S M, Lee S I. A unified approach to interpreting model predictions[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems,Long Beach, California, USA,December 4-9, ACM, 2017: 4768-4777. |
| [1] | 胡忠义, 税典程, 吴江. 中国上市公司数字化水平测度与演化研究——来自年报文本的经验证据[J]. 中国管理科学, 2025, 33(4): 36-49. |
| [2] | 许帅, 邵帅, 何贤杰. 业绩说明会前瞻性信息对分析师盈余预测准确性的影响[J]. 中国管理科学, 2025, 33(3): 34-44. |
| [3] | 李刚, 仇朝朝, 张志鹏, 秦思萌, 薛星楠. 基于多源文本数据和特征增强树模型的上市公司欺诈预测研究[J]. 中国管理科学, 2025, 33(11): 29-40. |
| [4] | 游万海, 陈森杰, 陈健永, 任英华. “多言寡行”环境责任表现对股价崩盘风险的影响——基于投资者情绪的中介效应[J]. 中国管理科学, 2025, 33(10): 12-23. |
| [5] | 陈艺云, 陈曼莲. 定性文本信息与信用评级:基于年报文本分析的研究[J]. 中国管理科学, 2023, 31(9): 94-104. |
| [6] | 陈艺云. 基于信息披露文本的上市公司财务困境预测:以中文年报管理层讨论与分析为样本的研究[J]. 中国管理科学, 2019, 27(7): 23-34. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||